Onboard high-definition audio chips are very common now. From the viewpoint of software, they support unbelievable quality of sound reproduction: 24 bits of precision at the 192 kHz sampling rate. The reality is in fact worse, as there is always noise in the analog output that the headphones are connected to.
I am not talking about the thermal noise or 1/f noise that is created intrinsically by every electronic device and sounds like a soft "shshsh...". These kinds of noise are important in radio receivers or tape recorders that have a high-gain amplifier needed to recover a weak incoming signal, but not in computers.
I am talking about the interference, where the signal in one wire (not intended to be played as sound) propagates into the other wire located nearby or to another circuit connected to the same badly-filtered power supply. The exact sound of such interference depends on what the computer is doing. If the computer is doing something periodically (e.g., drawing a scene on the screen 60 times a second, or filling a sound buffer in JACK 500 times a second), this unwanted sound becomes a tone, and thus becomes easily noticeable. Here are the steps that helped me to reduce it in my desktop computer based on the Intel DG965SS motherboard.
First, the wire that picks up a lot of interference is the wire that connects the front headphone socket to the motherboard. It is better to avoid using the front socket at all, and plug the headphones (if the cord is long enough) into the green socket on the back of the motherboard. This way, the cord is screened from the noisy components inside the computer by the metallic case.
Second, it may be a good idea to reduce the time variations of the power consumption of various components in the computer.
E.g., the processor draws a lot of power when it is busy, but consumes less power when it is idle. When it switches between the busy and idle states periodically, it creates a tone in the power line, and that tone ultimately gets to the sound chip output. So, to suppress the tone, one solution would be to keep the processor always busy. This is what the "idle=poll" Linux kernel parameter does. Note that a busy processor runs hot (in my computer, at 47.0°C), so think twice before using this option. A less dragonian solution would be to pass the "max_cstate=3" parameter to the "processor" module. (A big "thanks" goes to Robert Hancock and Sitsofe Wheeler who suggested these parameters.)
The other component of the computer that periodically draws a lot of power is the video card. But it is easier to keep it mostly idle, not busy. The most common desktop process that keeps the GPU busy is a compositing window manager (kwin or compiz). So, disable desktop effects, and enjoy better sound quality.
Saturday, December 27, 2008
Saturday, December 13, 2008
JPEG quality is a meaningless number
Suppose that a web designer tells you:
Ignore the bit about the desired quality, especially if the web designer uses Adobe Photoshop and has tested his page only with images made with Photoshop. The reason is that the same number yields different quality in different applications. Let me demonstrate this using this original image.
The image has been resized to 400x300 pixels using Photoshop (that contains Adobe's own JPEG encoder) and GIMP (that uses libjpeg from IJG, as many web scripts do). Here are the screenshots of the corresponding settings.
Photoshop:
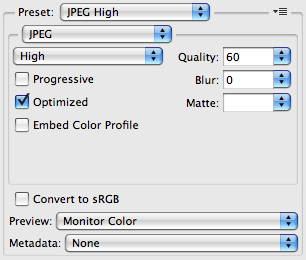
GIMP:
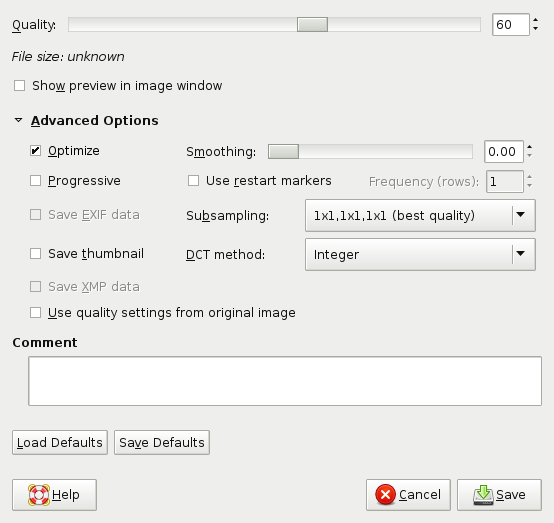
As you see, both programs are set to optimization of Huffman tables, no smoothing, no chroma subsampling, and 60% quality according to their scales. Here are the resulting images.
Photoshop:

GIMP:

As you can see, the image created by Adobe Photoshop is almost perfect, while on the image created with GIMP there are visible artifacts in the form of double contours around the parrots in the top row. This is not what the web designer wanted.
Here are some statistics. The image made with Photoshop takes 46 KB, while the image made with GIMP takes only 26 KB.
The quantization tables stored in the JPEG files are also different. If you don't know how to interpret numbers in them: the bigger the number is, the more precision is lost. The closer the number is to the right or bottom, to finer horizontal or vertical details it corresponds.
Photoshop:
GIMP:
So indeed, Photoshop saves more details than GIMP at the indicated settings. The meaningless quality percentages match, the actual quality settings don't. In order to achieve in GIMP (and thus in web scripts that use the same libjpeg library from IJG) what the web designer actually meant, one would need to use quality=85% or so.
Your task is to make a script that creates images for this web page. The images should be in JPEG format, have such-and-such dimensions, and their quality should be this number of percent.
Ignore the bit about the desired quality, especially if the web designer uses Adobe Photoshop and has tested his page only with images made with Photoshop. The reason is that the same number yields different quality in different applications. Let me demonstrate this using this original image.
{kind=link}
The image has been resized to 400x300 pixels using Photoshop (that contains Adobe's own JPEG encoder) and GIMP (that uses libjpeg from IJG, as many web scripts do). Here are the screenshots of the corresponding settings.
Photoshop:
GIMP:
As you see, both programs are set to optimization of Huffman tables, no smoothing, no chroma subsampling, and 60% quality according to their scales. Here are the resulting images.
Photoshop:
GIMP:
As you can see, the image created by Adobe Photoshop is almost perfect, while on the image created with GIMP there are visible artifacts in the form of double contours around the parrots in the top row. This is not what the web designer wanted.
Here are some statistics. The image made with Photoshop takes 46 KB, while the image made with GIMP takes only 26 KB.
The quantization tables stored in the JPEG files are also different. If you don't know how to interpret numbers in them: the bigger the number is, the more precision is lost. The closer the number is to the right or bottom, to finer horizontal or vertical details it corresponds.
Photoshop:
Luminance Chrominance
6 4 4 6 9 11 12 16 7 7 13 24 26 31 31 31
4 5 5 6 8 10 12 12 7 12 16 21 31 31 31 31
4 5 5 6 10 12 14 19 13 16 17 31 31 31 31 31
6 6 6 11 12 15 19 28 24 21 31 31 31 31 31 31
9 8 10 12 16 20 27 31 26 31 31 31 31 31 31 31
11 10 12 15 20 27 31 31 31 31 31 31 31 31 31 31
12 12 14 19 27 31 31 31 31 31 31 31 31 31 31 31
16 12 19 28 31 31 31 31 31 31 31 31 31 31 31 31
GIMP:
Luminance Chrominance
13 9 8 13 19 32 41 49 14 14 19 38 79 79 79 79
10 10 11 15 21 46 48 44 14 17 21 53 79 79 79 79
11 10 13 19 32 46 55 45 19 21 45 79 79 79 79 79
11 14 18 23 41 70 64 50 38 53 79 79 79 79 79 79
14 18 30 45 54 87 82 62 79 79 79 79 79 79 79 79
19 28 44 51 65 83 90 74 79 79 79 79 79 79 79 79
39 51 62 70 82 97 96 81 79 79 79 79 79 79 79 79
58 74 76 78 90 80 82 79 79 79 79 79 79 79 79 79
So indeed, Photoshop saves more details than GIMP at the indicated settings. The meaningless quality percentages match, the actual quality settings don't. In order to achieve in GIMP (and thus in web scripts that use the same libjpeg library from IJG) what the web designer actually meant, one would need to use quality=85% or so.
Saturday, December 6, 2008
A way to lose a file
The ln command from GNU coreutils warns when the source and the destination of the attempted hardlink are the same file, and does nothing:
Its counterpart from FreeBSD, however, doesn't warn. Instead, it erases the file.
$ echo 123 >testfile
$ ls -l testfile
--rw-r--r-- 1 aep aep 4 Dec 6 15:08 testfile
$ ln testfile testfile
ln: creating hard link `testfile': File exists
$ ln -f testfile testfile
ln: `testfile' and `testfile' are the same file
$ ls -l testfile
--rw-r--r-- 1 aep aep 4 Dec 6 15:08 testfile
Its counterpart from FreeBSD, however, doesn't warn. Instead, it erases the file.
$ echo 123 >testfile
$ ls -l testfile
--rw-r--r-- 1 aep aep 4 Dec 6 15:08 testfile
$ ln testfile testfile
ln: testfile: No such file or directory
$ ls -l testfile
ls: testfile: No such file or directory
Fixes
Some time ago, I mentioned in this blog some bugs that annoyed me. Some of them got fixes:
- Speaker-test fails with pcsp: fixed in ALSA Git.
- Kernel panic due to iwlwifi: fixed in linux-2.6.27.6
- Internal compiler error in GCC-4.3 on proprietary code: fixed in GCC SVN, the fix will be a part of GCC-4.4.
Sunday, November 23, 2008
Linux audio sucks
because of bugs in drivers, libraries, and applications. Here are some of them. They are quite real, because they interfere with my not-so-unrealistic requirements (play music through headphones connected to the onboard HD audio chip, make some noise with the PC speaker when someone calls me via SIP, and copy sound from my TV tuner to the HD audio chip when I watch TV).
- In a driver. Take, for example, saa7134-alsa (a kernel module that allows recording audio from SAA713X-based TV tuners). It advertises support for the following sample rates: 32 kHz and 48 kHz. What it fails to mention is that it doesn't support recording at 48 kHz except for the case of "original SAA7134 with the MIXER_ADDR_LINE2 capture source". In all other cases (e.g., SAA7133 with the MIXER_ADDR_TVTUNER capture source), it gives out 32 kHz samples, but mislabels them as 48 kHz. Thus, applications such as MPlayer have to be configured to use only the 32 kHz sample rate. Not a big problem if such configuration is possible (i.e.: if not using PulseAudio together with HAL), but still a bug.
- In the ALSA library. Today I discovered that the PC speaker at home no longer plays ring tones in SIP clients. It did work before, but I can no longer find a working revision. While testing this sound device with speaker-test, I found this floating point exception inside the ALSA library.
- In applications. The most frequent bug is that an application doesn't have a way to use an arbitrary ALSA device, and instead has a drop-down box with pre-defined choices. Such applications often cannot work with Bluetooth headsets (that I don't have), FireWire audio cards (that I don't have either), and through non-default PulseAudio devices (and this has bit me when I tried to use Linphone with PulseAudio - I couldn't configure it to use the PC speaker through PulseAudio). What's even worse is that HAL endorses this faulty "drop-down box" enumeration scheme.
Sunday, November 16, 2008
Strange backtrace
Some time ago I had to debug a strange crash. It was in a multithreaded program and manifested itself only on FreeBSD i386. The code (with all the needed declarations included, seemingly irrelevant details removed, and everything renamed) looks like this:
The test file is not created, and the segfault looks like this:
At this point, everything looks valid, including the "this" pointer. By all applicable logic, the program just cannot segfault by calling open() with valid parameters. So I started adding debugging printf() statements. The statement just before the call to play_with_strange_thing() worked fine, and none of the statements inside play_with_strange_thing() worked. Moreover, when I added a printf() as the very first line of strange_container::play_with_strange_thing() and ran gdb on the result, it showed this printf() in the backtrace!
So, I didn't believe my eyes. I thought (wrongly) that printf() and buffering somehow interacts with the segfault, and thus invented a different mechanism to find out whether a certain line of code was reached by the program. Namely, I replaced all my debugging printf() calls in strange_container::play_with_strange_thing() with throwing exceptions, with the intention to remove them one-by-one:
This worked. I knew for sure that point (2) was reached, and point (3) was't. So there is something bad with creation of the strange thing that, however, doesn't cause gdb to complain about its constructor.
So, I had to take another look into the implementation of the strange_thing class. The issue was actually with the huge size of the object (several megabytes)! So, no wonder that it overflowed the thread stack. You can reproduce the crash on your own system by replacing "lots of implementation details" with "char c[2000000];", implementing the strange_thing default constructor, and running with a low-enough "ulimit -s" setting.
As the reason of the crash became known, it was an easy matter to fix properly, by not creating huge objects on the stack.
#include <cstdio>
#include <cstring>
#include <cerrno>
#include <fcntl.h>
#include <unistd.h>
#include <exception>
class system_error : public exception
{
public:
system_error() throw() :error_text(strerror(errno)) {}
virtual const char* what() const throw() { return error_text; }
private:
const char* error_text;
};
class strange_thing
{
public:
strange_thing(); // fills in some useful defaults
private:
// lots of implementation details
};
class strange_container
{
public:
strange_container();
~strange_container() { if (fd != -1) close(fd); }
void play_with_strange_thing(const char* filename);
private:
int fd;
};
strange_container::strange_container()
: fd(-1)
{
play_with_strange_thing("test.file");
}
void strange_container::play_with_strange_thing(const char* filename)
{
fd = open(filename, O_CREAT | O_TRUNC | O_RDWR, 0777);
if (fd == -1)
throw system_error();
strange_thing ss;
/* here goes some code that uses ss and fd */
}
// well, actually it is not the main function, but something buried in a thread
int main(int argc, char* argv[])
{
strange_container c;
return 0;
}
The test file is not created, and the segfault looks like this:
[aep@bsd1 ~/crashtest]$ gdb ./a.out
GNU gdb 6.1.1 [FreeBSD]
Copyright 2004 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i386-marcel-freebsd"...
(gdb) run
Starting program: /usr/home/aep/crashtest/a.out
[New LWP 100043]
[New Thread 0x28301100 (LWP 100043)]
Program received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0x28301100 (LWP 100043)]
strange_container::play_with_strange_thing (this=0x28306098,
filename=0x8048c33 "test.file") at crashtest.cpp:57
57 fd = open(filename, O_CREAT | O_TRUNC | O_RDWR, 0666);
At this point, everything looks valid, including the "this" pointer. By all applicable logic, the program just cannot segfault by calling open() with valid parameters. So I started adding debugging printf() statements. The statement just before the call to play_with_strange_thing() worked fine, and none of the statements inside play_with_strange_thing() worked. Moreover, when I added a printf() as the very first line of strange_container::play_with_strange_thing() and ran gdb on the result, it showed this printf() in the backtrace!
So, I didn't believe my eyes. I thought (wrongly) that printf() and buffering somehow interacts with the segfault, and thus invented a different mechanism to find out whether a certain line of code was reached by the program. Namely, I replaced all my debugging printf() calls in strange_container::play_with_strange_thing() with throwing exceptions, with the intention to remove them one-by-one:
void strange_container::play_with_strange_thing(const char* filename)
{
throw system_error(); // (1)
fd = open(filename, O_CREAT | O_TRUNC | O_RDWR, 0777);
throw system_error();
if (fd == -1)
throw system_error();
throw system_error(); // (2)
strange_thing ss;
throw system_error(); // (3)
/* here goes some code that uses ss and fd, err... throws system_error() */
}
This worked. I knew for sure that point (2) was reached, and point (3) was't. So there is something bad with creation of the strange thing that, however, doesn't cause gdb to complain about its constructor.
So, I had to take another look into the implementation of the strange_thing class. The issue was actually with the huge size of the object (several megabytes)! So, no wonder that it overflowed the thread stack. You can reproduce the crash on your own system by replacing "lots of implementation details" with "char c[2000000];", implementing the strange_thing default constructor, and running with a low-enough "ulimit -s" setting.
As the reason of the crash became known, it was an easy matter to fix properly, by not creating huge objects on the stack.
Saturday, October 25, 2008
Unexpected warning
Today I refactored a function in my C program in order to make it more readable and remove special-casing. What came unexpected is that I got a new warning in a function that I didn't touch. While this sounds strange, here is a very simple example that shows how it could happen.
This is the function that I didn't touch, but that will, at the end, get a warning:
Here is a caller, just to make it sure that a static function is used:
With all of the above, there is no warning, even when "-O3 -Wall" flags are passed to gcc. Now add this (in the real program, this is the result of value propagation over various branches):
The intention is to attenuate the unneeded term enough so that it doesn't matter, and use the general two-band case. With gcc-4.3.1 -O3 -Wall, the result, referring to the line in add_db() where a is compared with b, is:
So it looks like gcc inlined everything and attempted to test whether peak_db[0] < peak_db[0] - 200. Because C compilers are allowed to think that signed overflow never occurs, this is always false (as intended). However, tests of this form are often incorrectly used as security checks, that's why the warning.
This is the function that I didn't touch, but that will, at the end, get a warning:
extern const int db_to_add[32];
static int add_db(int a, int b)
{
if (a < b) {
int tmp = a;
a = b;
b = tmp;
}
if (a - b >= 32)
return a;
return a + db_to_add[a - b];
}
Here is a caller, just to make it sure that a static function is used:
int peak_db[32];
static int noise(int band1, int band2, int spectrum1, int spectrum2)
{
/* actually a lot more complex, but the idea is that
it takes two bands, except for special cases */
int noise1 = peak_db[band1] + spectrum1;
int noise2 = peak_db[band2] + spectrum2;
return add_db(noise1, noise2);
}
int valid_use(int b, int s)
{
/* a dummy warning-free function
only for the purpose of this blog post */
return noise(b, b + 1, 0, s);
}
With all of the above, there is no warning, even when "-O3 -Wall" flags are passed to gcc. Now add this (in the real program, this is the result of value propagation over various branches):
int trigger_warning()
{
return noise(0, 0, 0, -200);
}
The intention is to attenuate the unneeded term enough so that it doesn't matter, and use the general two-band case. With gcc-4.3.1 -O3 -Wall, the result, referring to the line in add_db() where a is compared with b, is:
warning: assuming signed overflow does not occur when assuming that (X - c) > X is always false
So it looks like gcc inlined everything and attempted to test whether peak_db[0] < peak_db[0] - 200. Because C compilers are allowed to think that signed overflow never occurs, this is always false (as intended). However, tests of this form are often incorrectly used as security checks, that's why the warning.
Thursday, October 23, 2008
Don't believe rrdtool
rrdtool is the industry standard for plotting time-dependent data (t.g., for monitoring). However, Debian's rrdtool 1.3.1-4 can create misleading plots. Here is how to reproduce.
First, create a round-robin database that will hold our test data.
Then, populate it with numbers:
The number before the semicolon is a UNIX timestamp, and the number after the semicolon is the corresponding value. As you see from the numbers, the value is slightly above 1.35 million and slowly grows in the beginning of the period.
Let's plot it:
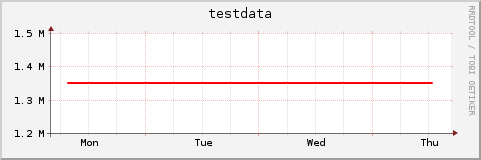
Indeed, there is not much change. But let's suppose that we are really interested in the small change that happened over the week.
Let's use the alternative autoscaling option that, according to the manual page, is designed specifically for such cases:
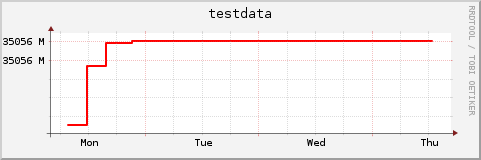
What? The plot says that the value is 35000M, which is waaaay wrong.
I don't know yet whether this bug is Debian-spedific, but that's enough for discouraging me from using -A and -Y options.
Update: not a bug. The label is just cut off from the left. Here is the correct plot:
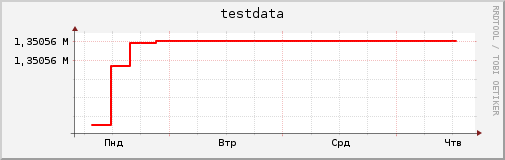
Although I must say that MS Excel handles this case better: it replaces numbers that don't fit with "###". Such placeholder (no number) is better than a wrong (chopped) number.
First, create a round-robin database that will hold our test data.
rrdtool create testdata.rrd --start 1224453000 --step 1800 \
DS:testdata:GAUGE:28000:0:U RRA:LAST:0.5:1:1800
Then, populate it with numbers:
rrdtool update testdata.rrd 1224453300:1350535
rrdtool update testdata.rrd 1224467700:1350545
rrdtool update testdata.rrd 1224482100:1350554
rrdtool update testdata.rrd 1224496500:1350560
rrdtool update testdata.rrd 1224514800:1350562
rrdtool update testdata.rrd 1224539700:1350562
rrdtool update testdata.rrd 1224557700:1350562
rrdtool update testdata.rrd 1224576000:1350562
rrdtool update testdata.rrd 1224590100:1350562
rrdtool update testdata.rrd 1224604800:1350562
rrdtool update testdata.rrd 1224622500:1350562
rrdtool update testdata.rrd 1224636900:1350562
rrdtool update testdata.rrd 1224651300:1350562
rrdtool update testdata.rrd 1224669300:1350562
rrdtool update testdata.rrd 1224683700:1350562
rrdtool update testdata.rrd 1224698100:1350562
rrdtool update testdata.rrd 1224712500:1350562
rrdtool update testdata.rrd 1224730500:1350562
rrdtool update testdata.rrd 1224744900:1350562
The number before the semicolon is a UNIX timestamp, and the number after the semicolon is the corresponding value. As you see from the numbers, the value is slightly above 1.35 million and slowly grows in the beginning of the period.
Let's plot it:
rrdtool graph testdata.png -t testdata --start 1224453000 --end 1224757634 \
DEF:testdata=testdata.rrd:testdata:LAST 'LINE2:testdata#ff0000'

Indeed, there is not much change. But let's suppose that we are really interested in the small change that happened over the week.
Let's use the alternative autoscaling option that, according to the manual page, is designed specifically for such cases:
rrdtool graph testdata-bug.png -t testdata --start 1224453000 --end 1224757634 \
-A -Y DEF:testdata=testdata.rrd:testdata:LAST 'LINE2:testdata#ff0000'

What? The plot says that the value is 35000M, which is waaaay wrong.
I don't know yet whether this bug is Debian-spedific, but that's enough for discouraging me from using -A and -Y options.
Update: not a bug. The label is just cut off from the left. Here is the correct plot:
rrdtool graph testdata-bug.png -t testdata --start 1224453000 --end 1224757634 \
-A -Y -L 10 DEF:testdata=testdata.rrd:testdata:LAST 'LINE2:testdata#ff0000'

Although I must say that MS Excel handles this case better: it replaces numbers that don't fit with "###". Such placeholder (no number) is better than a wrong (chopped) number.
Sunday, October 12, 2008
Porting C/C++ code from Unix to Win32
At Yandex, some employees use Microsoft Visual Studio on Windows for compiling and debugging their code, some use gcc and gdb on Linux or FreeBSD (via ssh). And thus, portability problems arise. Here is one example.
A chunk of new code was written on FreeBSD that, essentially, opens a file (or maybe stdin), determines which plugin (i.e., shared library) to load, and passes the file descriptor to a function in the plugin. A natural design for Unix, however, it doesn't work for Windows: the file descriptors opened with open() are valid only in the same module (i.e., DLL or application) that opened them. It appears that one has to use _get_osfhandle() and _open_osfhandle() Win32 functions to overcome this limitation. That's just ugly.
Just for fun, I also tried to rebuild my own C code (not related to my work at Yandex), on Windows with Microsoft Visual Studio. This, obviously, resulted in problems:
A chunk of new code was written on FreeBSD that, essentially, opens a file (or maybe stdin), determines which plugin (i.e., shared library) to load, and passes the file descriptor to a function in the plugin. A natural design for Unix, however, it doesn't work for Windows: the file descriptors opened with open() are valid only in the same module (i.e., DLL or application) that opened them. It appears that one has to use _get_osfhandle() and _open_osfhandle() Win32 functions to overcome this limitation. That's just ugly.
Just for fun, I also tried to rebuild my own C code (not related to my work at Yandex), on Windows with Microsoft Visual Studio. This, obviously, resulted in problems:
- The Microsoft compiler doesn't have such standard C99 headers as <stdint.h>. I had to download this header from the msinttypes project.
- When compiling C files, the compiler doesn't recognize the "inline" keyword and the definition for int64_t from the <stdint.h> header doesn't work. Both issues were fixed with the /TP switch that tells the compiler to treat the code as C++.
- The compiler warns about the POSIX function open() and suggests to use the "standard" _open() function. What standard does it talk about?
- Well, the standard C function for opening files is actually fopen(), so I converted my program to use that. Guess what? A warning saying that fopen() is deprecated and suggesting to use fopen_s() that actually exists only in Microsoft compilers.
Saturday, September 27, 2008
Kernel panic

When I moved to another room in the office, my laptop started getting this kernel panic. So far, this means that I can't use the wireless network. I can work around this by either blacklisting the iwl4965 module or by turning the wireless card off with the hardware rfkill switch.
Maybe related: this laptop gets "ACPI: EC: non-query interrupt received, switching to interrupt mode" during boot.
I will report this panic to both the debian bug tracker and the linux-wireless list, let's see how they resolve it.
Saturday, September 20, 2008
Wrong macro
Here is how you shouldn't test for old compilers:
Reason: the workaround will also be applied to non-Microsoft compilers, e.g., gcc. Here is a more correct version:
#if _MSC_VER < 1400
/* some workaround */
#endifReason: the workaround will also be applied to non-Microsoft compilers, e.g., gcc. Here is a more correct version:
#if defined(_MSC_VER) && _MSC_VER < 1400
/* some workaround */
#endif
Thursday, September 18, 2008
Recording SIP conversations
My chief prefers to use SIP (voice conversations) instead of Jabber (text messaging). The problem is that he sometimes overloads me with a lot of information, and later I forget 90%. This is not a problem with Jabber, as there are logs. However, I don't know any SIP client that supports recording of conversations out of the box.
Here is my solution. You need alsa-lib 1.0.17 or later (i.e., if you are using Debian Lenny, due to the freeze, you'll have to fetch libasound2 and libasound2-dev from experimental). Create the subdirectory named "voice" in your home directory. Add these lines to $HOME/.asoundrc:
Then, configure your SIP client (I use twinkle) as follows. ALSA device for rings: "default", ALSA speaker: "voice", ALSA microphone: "voice", Play back ring tone when the network doesn't: disable. As the result, ALSA library will write the following files into the voice directory: p, c, p.0001, c.0001, p.0002, c.0002, and so on (the number is incremented for each new call). All these files are in wav format, "p" files correspond to the remote side, and "c" files contain what you spoke into the microphone. It appears that it is impossible to record both parties of the conversation into one file using only built-in features that come with ALSA.
To play back the conversation, do:
This will cause two aplay processes to be started in parallel, with their outputs mixed. Or, you can make one mixed wav file with sox:
Here is my solution. You need alsa-lib 1.0.17 or later (i.e., if you are using Debian Lenny, due to the freeze, you'll have to fetch libasound2 and libasound2-dev from experimental). Create the subdirectory named "voice" in your home directory. Add these lines to $HOME/.asoundrc:
pcm.voice {
type asym
playback.pcm {
type file
file "/home/user/voice/p"
slave.pcm "default"
format "wav"
truncate 0
}
capture.pcm {
type file
file "/home/user/voice/c"
slave.pcm "default"
format "wav"
truncate 0
}
}Then, configure your SIP client (I use twinkle) as follows. ALSA device for rings: "default", ALSA speaker: "voice", ALSA microphone: "voice", Play back ring tone when the network doesn't: disable. As the result, ALSA library will write the following files into the voice directory: p, c, p.0001, c.0001, p.0002, c.0002, and so on (the number is incremented for each new call). All these files are in wav format, "p" files correspond to the remote side, and "c" files contain what you spoke into the microphone. It appears that it is impossible to record both parties of the conversation into one file using only built-in features that come with ALSA.
To play back the conversation, do:
aplay p.0002 & aplay c.0002
This will cause two aplay processes to be started in parallel, with their outputs mixed. Or, you can make one mixed wav file with sox:
sox -m c.0002 p.0002 -f wav talk0002.wav
Wednesday, September 17, 2008
gcc-4.3 troubles
After obtaining access to the CVS server at Yandex, I tried to build some internal utilities for daily use (e.g., for examining database contents) on my work laptop. The first attempt failed, because Debian Lenny comes with gcc-4.3.1, and the official build machines (that I was in fact supposed to use instead of the laptop) still use gcc-4.2.x.
First, some of the "known good" snapshots of external projects that are used by the to-be-built utilities have gcc-4.3 related issues. Fortunately, Debian's bug and package database was very helpful, and I was able to extract the needed patches.
Second, gcc-4.3 added some new warnings, and the build system is set up to use -Werror by default. While some of the new warnings are helpful, others are not. Try, e.g., compiling this simple function with g++ -Wconversion -c test.cpp:
Result:
I.e., almost every in-place mathematical operation with shorts and chars results in warnings! With -Werror, this means errors in many files. Obviously, this isn't worth fixing, so I removed -Wconversion from the compiler flags in my checkout. Similar bugs are already recorded in GCC bugzilla.
Third, even after fixing fixable warnings and removing -Wconversion, I hit an internal compiler error. Since I found no similar reports (the error manifested itself on proprietary code, after all), I reduced the testcase and submitted it to GCC bugzilla.
After that, I gave up. I posted my changes to the internal code review list (just so that they don't get lost), switched the compiler to gcc-4.2 (it is available in Debian side-by-side with 4.3), and compiled what I needed without further problems.
BTW, Debian still uses gcc-4.1.2 for compiling their kernels. It would be interesting to know why.
First, some of the "known good" snapshots of external projects that are used by the to-be-built utilities have gcc-4.3 related issues. Fortunately, Debian's bug and package database was very helpful, and I was able to extract the needed patches.
Second, gcc-4.3 added some new warnings, and the build system is set up to use -Werror by default. While some of the new warnings are helpful, others are not. Try, e.g., compiling this simple function with g++ -Wconversion -c test.cpp:
typedef unsigned char uint8_t;
void grow(uint8_t & u)
{
u *= 7;
}
Result:
test.cpp: In function 'void grow(uint8_t&)':
test.cpp:4: warning: conversion to 'unsigned char' from 'int' may alter its value
I.e., almost every in-place mathematical operation with shorts and chars results in warnings! With -Werror, this means errors in many files. Obviously, this isn't worth fixing, so I removed -Wconversion from the compiler flags in my checkout. Similar bugs are already recorded in GCC bugzilla.
Third, even after fixing fixable warnings and removing -Wconversion, I hit an internal compiler error. Since I found no similar reports (the error manifested itself on proprietary code, after all), I reduced the testcase and submitted it to GCC bugzilla.
After that, I gave up. I posted my changes to the internal code review list (just so that they don't get lost), switched the compiler to gcc-4.2 (it is available in Debian side-by-side with 4.3), and compiled what I needed without further problems.
BTW, Debian still uses gcc-4.1.2 for compiling their kernels. It would be interesting to know why.
Tuesday, September 16, 2008
New job!


Since September 15, 2008, I work at Yandex, as a developer in the Image search department. I am busy with bash scripts, C++ and even XML. My work computer is a Fujitsu Siemens S laptop, and I installed Debian Lenny there. One strange thing about this job is that I have never seen my chief: he is in Moscow, and all conversations with him are via Jabber and SIP.
The office in Yekaterinburg is clean, there are nice flowers in front of the building, and my colleagues seem to enjoy working there. Our windows (on the fifth floor) remain lit even at 10 PM.
Subscribe to:
Comments (Atom)